2024-05-02
Parser Combinator
Indexes
学 moonbit 的过程中找到官网写的一个教程《现代编程思想》,写得非常好:
尤其是其中的 parser combinator 又一次刷新了我对程序表达力的看法
# Parser Combinator 是什么呢? ↵
所谓「词法解析」就是将扁平的字符串转为某种带结构的构造,比如解析字符串的
"[1,23]"
使其变成 JS Array 对象 [1, 23]
,而 parser combinator 是一种写「词法解析」的通用范式,它将 parser 概括为判断字符串的第一个元素是否满足「规则」然后通过组合子的方式将这些「规则」构造成更复杂的「规则」最终得到完整的「词法解析」 —— 总之,利用这样的方式我们可以将下图里这样的表达式字符串转为某种描述表达式的 ADT:
基于这样的模式来写词法分析爽的不行(⬅️ 刚通宵完现在爽到根本没有困意)
具体直接看代码吧,曼妙无需多言(上次这么爽还是上次写 lisp 解释器的时候)
下面这个链接是 Moonbit 在线 VSCode Playground 分享代码,建议右侧运行并全屏使用(文件右键可以执行我上面的代码)
看完真的醍醐灌顶,深刻领教了
Combinator
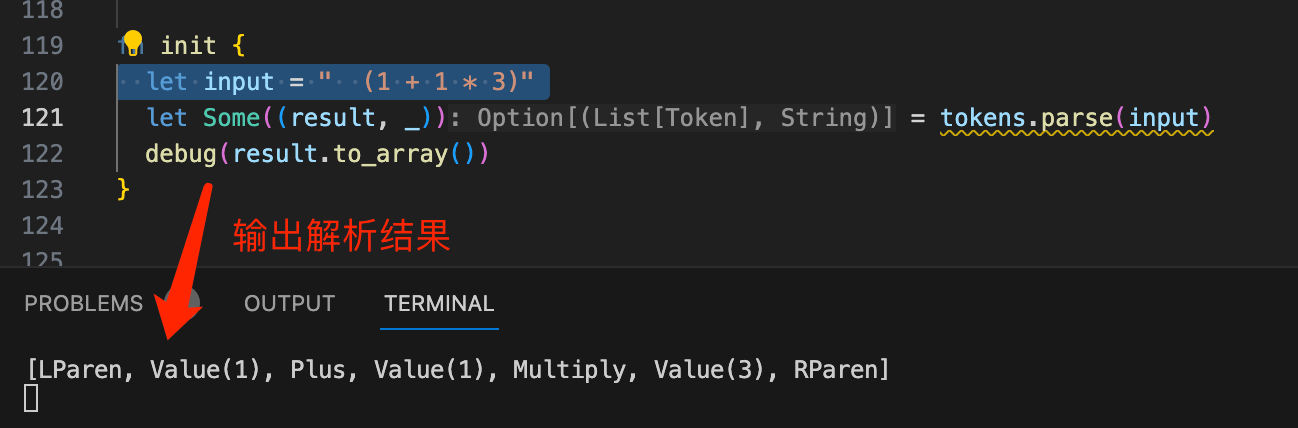
体现的函数式思想,再配合 ADT 带上满血版模式匹配写 parser 爽到飞起,现在再看大学编译原理用 C 写的各种 for 循环然后 getChar 风格的词法解析就会感觉丑到无法入眼了。(以下是完整代码,再贴一遍233)000enum Token { 001 Value(Int) 002 LParen; 003 RParen; 004 Plus; 005 Minus; 006 Multiply; 007 Divide; 008} derive(Debug) 009 010type Lexer[V] (String) -> Option[(V, String)] 011 012fn parse[V](self: Lexer[V], str: String) -> Option[(V, String)] { 013 (self.0)(str) 014} 015 016fn pchar(predicate: (Char) -> Bool) -> Lexer[Char] { 017 Lexer(fn (input) { 018 if input.length() > 0 && predicate(input[0]) { 019 let start = 1 020 Some((input[0], input.substring(~start))) 021 } else { 022 None 023 } 024 }) 025} 026 027let symbol: Lexer[Token] = pchar(fn (input) { 028 match input { 029 '+' | '-' | '*' | '/' | '(' | ')' => true 030 _ => false 031 } 032}).map(fn { 033 '+' => Plus 034 '-' => Minus 035 '*' => Multiply 036 '/' => Divide 037 '(' => LParen 038 ')' => RParen 039}) 040 041let whitespace: Lexer[Char] = pchar(fn (input) { 042 match input { 043 ' ' => true 044 _ => false 045 } 046}) 047 048fn map[I, O](self: Lexer[I], f: (I) -> O) -> Lexer[O] { 049 Lexer(fn(input) { 050 let (value, rest) = self.parse(input)? 051 Some((f(value), rest)) 052 }) 053} 054 055fn and[V1, V2](self: Lexer[V1], parser2: Lexer[V2]) -> Lexer[(V1, V2)] { 056 Lexer(fn (input) { 057 let (value, rest) = self.parse(input)? 058 let (value2, rest2) = parser2.parse(rest)? 059 Some(((value, value2), rest2)) 060 }) 061} 062 063fn or[Value](self: Lexer[Value], parser2: Lexer[Value]) -> Lexer[Value] { 064 Lexer(fn (input) { 065 match self.parse(input) { 066 None => parser2.parse(input) 067 Some(_) as result => result 068 } 069 }) 070} 071 072fn many[Value](self: Lexer[Value]) -> Lexer[List[Value]] { 073 Lexer(fn (input) { 074 let mut rest = input 075 let mut cumul = List::Nil 076 while true { 077 match self.parse(rest) { 078 None => break 079 Some((value, new_rest)) => { 080 rest = new_rest 081 cumul = Cons(value, cumul) 082 } 083 } 084 } 085 Some((cumul.reverse(), rest)) 086 }) 087} 088 089let zero: Lexer[Int] = pchar(fn { ch => ch == '0' }) 090 .map(fn { _ => 0 }) 091 092let one_to_nine: Lexer[Int] = 093 pchar(fn { ch => ch.to_int() >= 0x31 && ch.to_int() <= 0x39 }) 094 .map(fn { ch => ch.to_int() - 0x30 }) 095 096let zero_to_nine: Lexer[Int] = 097 pchar(fn { ch => ch.to_int() >= 0x30 && ch.to_int() <= 0x39 }) 098 .map(fn { ch => ch.to_int() - 0x30 }) 099 100// number = %x30 / (%x31-39) *(%30-39) 101let value: Lexer[Token] = 102 zero.or( 103 one_to_nine.and( 104 zero_to_nine.many() 105 ).map(fn { 106 ((i, ls)) => ls.fold_left(fn (acc, cur) { 107 acc * 10 + cur 108 }, init=i) 109 }) 110 ).map(Token::Value) 111 112 113// 注意到输入流里有各种空格,因此完整 tokens 可以定义为下面这样: 114pub let tokens: Lexer[List[Token]] = 115 whitespace.many().and(value.or(symbol).and(whitespace.many())) 116 .map(fn { (_, (symbols, _)) => symbols }) 117 .many() 118 119fn init { 120 let input = " + 123 313 +- /*22" 121 let Some((result, _)) = tokens.parse(input) 122 debug(result.to_array()) 123}
下面是根据上面的 TS 版本
000// 根据 lexer.mbt 改的 ts 版 001type Char = string & { length: 1 }; 002 003type Token = ( 004 | { type: 'token-value', number: number } 005 | { type: 'token-plus' } 006 | { type: 'token-minus' } 007 | { type: 'token-multiply' } 008 | { type: 'token-divide' } 009 | { type: 'token-lparen' } 010 | { type: 'token-rparen' } 011) 012 013class Lexer<V> { 014 constructor( 015 public parse: (str: string) => null | [V, string] 016 ) {} 017 018 map<O>(f: (input: V) => O): Lexer<O> { 019 return new Lexer<O>(input => { 020 let res = this.parse(input) 021 if (res === null) return null; 022 const [value, rest] = res; 023 return [f(value), rest] 024 }) 025 } 026 027 and<V2>(parser2: Lexer<V2>): Lexer<[V, V2]> { 028 return new Lexer(input => { 029 const res1 = this.parse(input) 030 if (res1 === null) return null; 031 const [value1, rest1] = res1; 032 const res2 = parser2.parse(rest1); 033 if (res2 === null) return null; 034 const [value2, rest2] = res2; 035 return [[value1, value2], rest2] 036 }) 037 } 038 039 or(parser2: Lexer<V>): Lexer<V> { 040 return new Lexer(input => { 041 const res = this.parse(input) 042 if (res === null) return parser2.parse(input) 043 return res; 044 }) 045 } 046 047 many(): Lexer<V[]> { 048 return new Lexer(input => { 049 let rest = input 050 let cumul: V[] = [] 051 while (true) { 052 const res = this.parse(rest) 053 if (res === null) break; 054 const [value, newRest] = res; 055 rest = newRest; 056 cumul.push(value); 057 } 058 return [cumul, rest]; 059 }) 060 } 061} 062 063function pchar(predicate: (char: Char) => boolean): Lexer<Char> { 064 return new Lexer(input => { 065 if (input.length && predicate(input[0] as Char)) { 066 return [input[0] as Char, input.slice(1)] 067 } else { 068 return null; 069 } 070 }) 071} 072 073let symbol: Lexer<Token> = pchar(input => { 074 if (input === '+') return true 075 if (input === '-') return true 076 if (input === '*') return true 077 if (input === '/') return true 078 if (input === '(') return true 079 if (input === ')') return true 080 return false 081}).map(char => { 082 if (char === '+') return { type: 'token-plus' } as Token 083 if (char === '-') return { type: 'token-minus' } as Token 084 if (char === '*') return { type: 'token-multiply' } as Token 085 if (char === '/') return { type: 'token-divide' } as Token 086 if (char === '(') return { type: 'token-lparen' } as Token 087 if (char === ')') return { type: 'token-rparen' } as Token 088 throw new Error('不可能走到这里') 089}) 090 091let whitespace: Lexer<Char> = pchar(input => (input === ' ')); 092 093let zero: Lexer<number> = pchar(ch => ch === '0').map(i => 0) 094let oneToNine: Lexer<number> = ( 095 pchar(ch => !!(ch.charCodeAt(0) >= 0x31 && ch.charCodeAt(0) <= 0x39)) 096 .map(ch => ch.charCodeAt(0) - 0x30) 097) 098let zeroToNine: Lexer<number> = ( 099 pchar(ch => !!(ch.charCodeAt(0) >= 0x30 && ch.charCodeAt(0) <= 0x39)) 100 .map(ch => ch.charCodeAt(0) - 0x30) 101) 102 103let value: Lexer<Token> = ( 104 zero.or( 105 oneToNine.and( 106 zeroToNine.many() 107 ).map(input => { 108 const [i, ls] = input; 109 return ls.reduce((acc, cur) => acc * 10 + cur, i) 110 }) 111 ).map(number => ({ type: 'token-value', number })) 112); 113 114let tokens: Lexer<Token[]> = ( 115 whitespace.many().and(value.or(symbol).and(whitespace.many())) 116 .map(input => { 117 const [_0, [token, _1]] = input; 118 return token 119 }) 120 .many() 121); 122 123 124// test !! 125(() => { 126 let input = ' + 123 313 +- /*22'; 127 let res = tokens.parse(input) 128 console.log(res); 129})()