Indexes
八年前我还在读本科的时候,修过一门关于神经网络与模式识别的课程,虽然这门课不用怎么写代码,但是其内在的思想我到今天还是记忆深刻;近 2 年来,ChatGPT 后大模型是越来越火热了,其内在的核心仍然是神经网络,如果需要搞明白大模型的推理,其实就是在问神经网络如何解决问题 ? 本文将介绍神经网络的基本构造并解释大模型的推理是什么,从
出发自底向上构建对大模型的数学认知,最后会从技术的角度上点评下现在流行的一些 AI 术语
# 为什么写此文 ↵

本文虽说是浅谈,不过还是有点点门槛,如果读者能掌握矩阵和一点点偏导数的知识应该能比较顺畅的阅读本文,本文的目标是:
- 1.我一直对 LLM 底下的数学原理不甚了解, 尤其是其如何工作的, 没有一个自底向上的清晰认知;
- 2.另外一个则是实践一下费曼学习法: 自己学一遍然后写出来文章来验证自己的逻辑是否能推导出一个 make sense 自洽的推演
- 3.短期内成为 LLM 专家不可能,但是搞明白其核心逻辑预计是不难的,不然无法解释这东西为什么这么火, 我坚信任何技术都有核心脉络,即便是外行也能把握其基本概念,优雅的逻辑推演是一种美妙的价值,能跨越领域壁垒
- 4.然而市面上太多的 LLM 介绍文章很爱用什么什么比喻,甚至还在谈一些浮夸的概念,比如 AI 社区内特有的「大的要来了」、AI 觉醒、AI 量子云云,这些反而会造成更多的战争迷雾影响认知,然而对于大模型来说其底层依然是基于严格的数学和逻辑推演而来,仅靠比喻无法彻底理解:大模型推理底下是在做什么
本文面向读者:所有对 AI 原理感兴趣的技术人员、产品经理、亦或者需要系统性梳理建构自底向上的 AI 知识体系的学习者,另外特别备注给对 G 味敏感的读者:本文不含任何 AI 生成内容, 纯手写和校对请放心食用
# 什么是『智能』? 符号主义和联结主义 ↵
这是两类 “AI / 认知科学” 里的思维范式,符号主义认为只要有足够多的 “符号” 和 “语法规则” 便能推导出符号系统内所有命题,比如形式化验证系统则是符号主义下最典型的系统,其另外一个极度普及的工业成果则是目前业界广泛实践的各个语言里的静态类型系统,这类系统的特点就是有一套固定的规则和符号,依据规则推演而实现更复杂的且合法的符号构造,而这样的符号构造又能用来解决实际问题:比如定理证明、静态类型检查等等。
对于智能的构造,符号主义的观点相当朴素:「智能」也是可以被定义出来的,即可以找出足够多的形式化符号和语法规则并依据人类的逻辑和知识库做推演而实现人工智能。
—— 但是,事实上符号主义的 AI 研究这几十年一直处于低迷状态,原因是:智能体需要面对极度复杂多变的真实世界,无法做确定性验证,且不论从近现代的【哥德尔不完备原理(逻辑)】或者【量子不确定性原理(物理)】以及【混沌微扰理论(复杂系统工程)】等各个领域的理论出发,符号主义所要求的 “足够多的符号” 和 “语法规则” 不是人类能完成的工作,这几乎等价于:掌握无穷大 ∞
而联结主义的观点认为:人类的大脑每个神经元都很简单,但是数百亿神经元工作在一起就能涌现出人类智能,所以智能的构造应该源于简单结构的规模化联结/叠加,若能在很大程度上模拟出大规模的神经元信号传播及自学习or奖励机制,是否可以实现智能? 从这个角度出发,就是现今以神经网络为基础的当代 AI 研究的主流思路了,主张从已有的大规模数据出发找到 “最拟合” 的函数(模型)作为对智能的解释
# 进一步的例子:找出点的预测 ↵
两种主义仅是所代表的思维方式不同,它们不是互斥的,为更进一步理解两种主义的不同,我们可以简单的下定义,将 “智能” 定义为 “找到一个函数 f 实现对点的预测效果”,最后利用采集到的现实数据代入回这个函数计算来做验证以此判断智能程度,比如我们有得到一条漂亮的
直线散点数据:

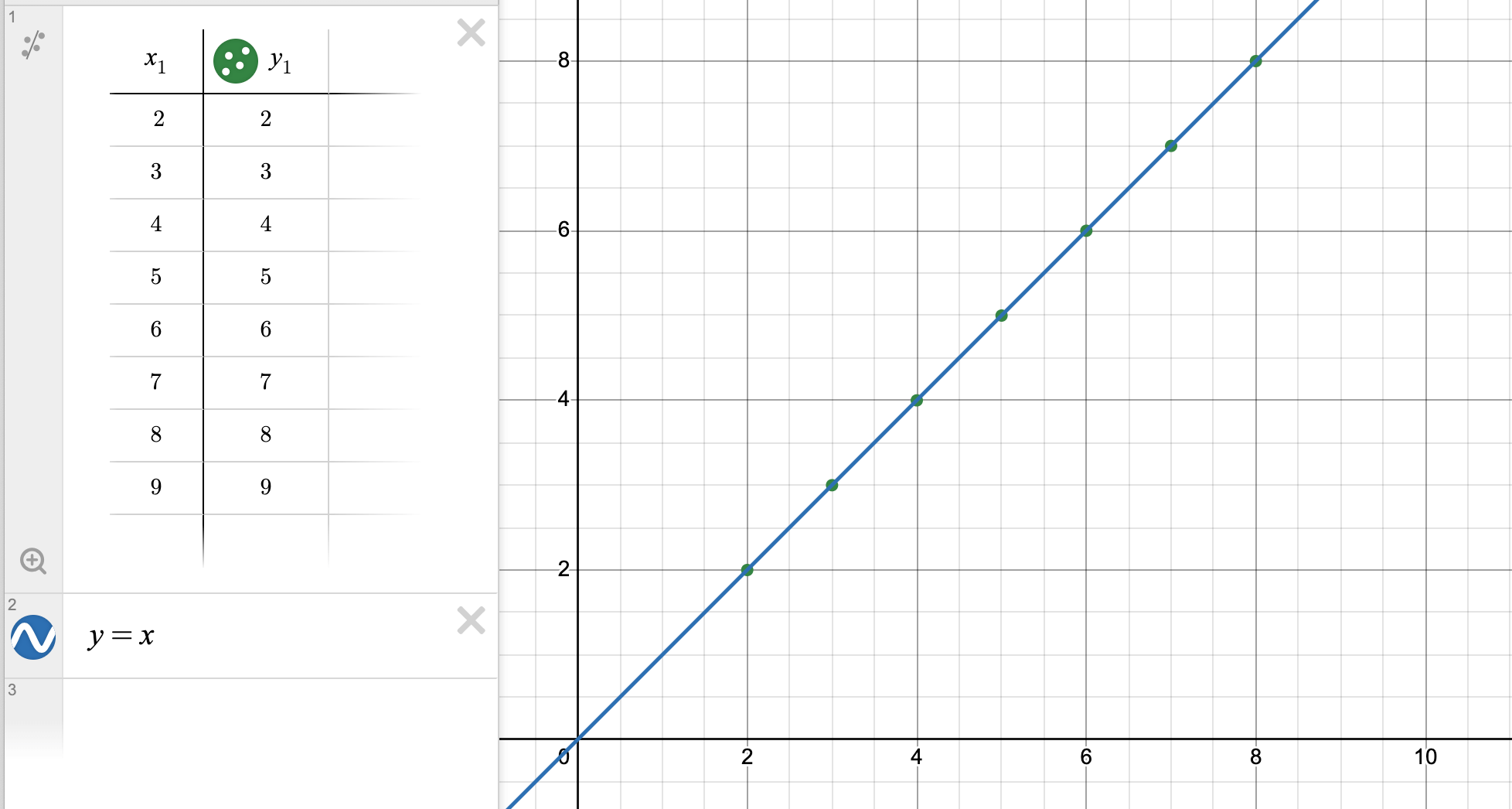
符号主义的观点认为:期望通过符号和逻辑规则推导,找到一个
f(...args)
从逻辑上推导出解,比如上图里所有的点显然满足 y = kx + b
这个函数,其中 k = 1
b = 0
因此很轻易的预测 当 x=10 时,y 绝对是 10
而联结主义的观点下:依据现有数据找出一个最拟合的
f(...args)
从概率上预测解,对于上图会在 x=10
时给出个置信预测,当然对于这个数据情况能给出极高的置信预测,即 当 x = 10 时, y 几乎是 10
(注意不是绝对)上述是一个简单的数值函数做例子,相信代表直觉理性的符号主义是多数人都很喜欢的(包括我),但是对于极度复杂而智能的函数来说,前者还能做到吗:
对于这类无法直接给出解析式或参数的函数,找出其「拟合预测」是一个不错的方向,如果这个函数变成下面这样的时候,这在某种程度上这是在定义怎样「说话」:
这正是目前 LLM 大模型的「文字接龙」递推循环了,不断从根据上下文猜字选取,然后插入到上下文末尾做循环递推多次猜字来实现「智能」 —— 如果我们能找到这个函数的拟合,是否能宣称我们实现了 “人工智能” ? 这个问题很有趣,这其实是一个哲学问题,看完本文我想读者会有自己的理解。
# 理解『拟合』以及评估拟合效果的『损失函数』 ↵
前面提到了,现实情况是极端复杂动态的,人类不可能找到这么个函数能永远解释一切,比如真实的点往往是离散混乱的,此时需要找到一个还算可以的函数来做拟合实现点的预测:

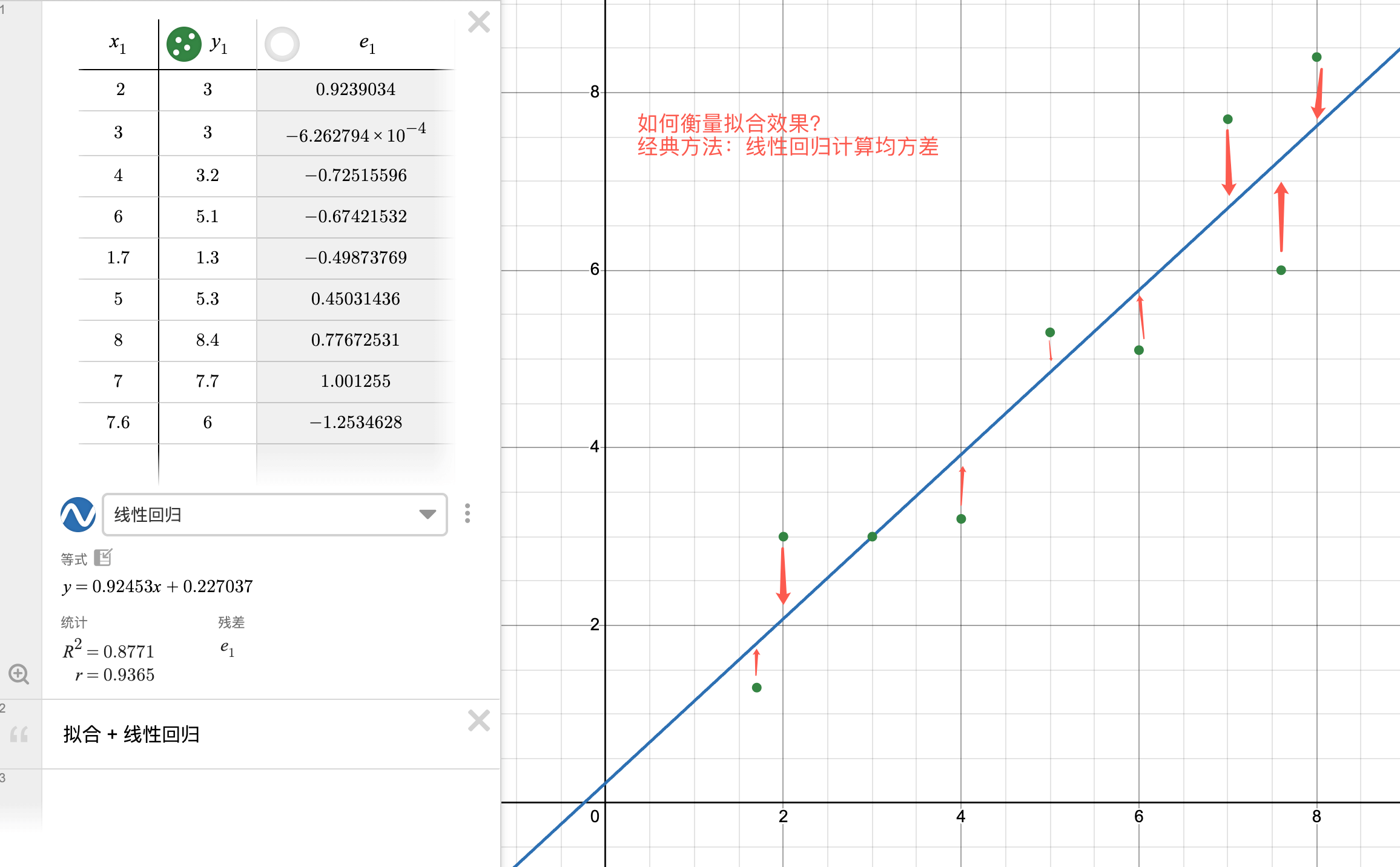
给定数据然后找出一个相对拟合的函数则是完全可能的,且已经有成熟的数学工具去做,一个最经典的方法就是线性回归和均方差,比如上图的那根蓝线,其计算方式如下,其中
为预测值:
这个公式其实就是上图里那些箭头的长度加起来计算一个平均数,用来衡量拟合的效果,显然此值越大则说明拟合效果越差,在学术上,用来评估拟合效果的函数称为 「损失函数 (Loss Function)」,此处的均方差则是其中最经典的一种损失函数, 当我们将直线的
带入回去即可得到一个更完整的式子:
最后,通过真实数据 x 和 y 来不断代入这个公式来计算损失函数的值,然后 “微调” 这个方程里的 K 和 B 的值,使损失函数
达到极小值,此时就可以说:拟合的够好了(训练好了)
—— 用数学语言来说,所谓训练就是在找出哪个
和
能使得
达到极小值,后面我将介绍如何依据真实数据来做 “微调” 达成训练目标:找到「损失函数的极小值」
# 从函数到『神经网络』和『正向传播 』 ↵
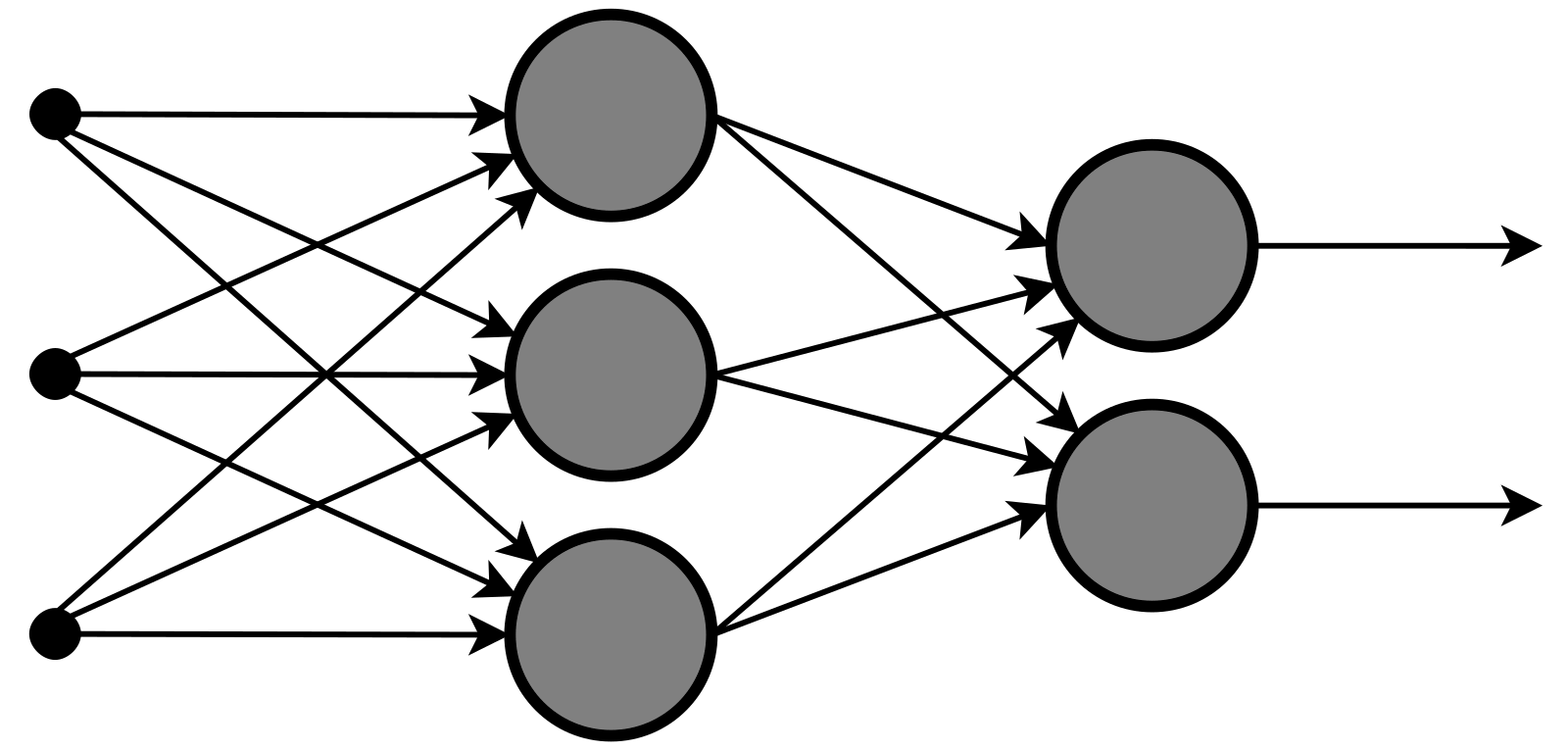
虽然说 “神经网络” 名字很高级,实际上它就是 f(x) 的图示,可以用参数和输出以及中间画箭头即可得到最简单的神经网络:

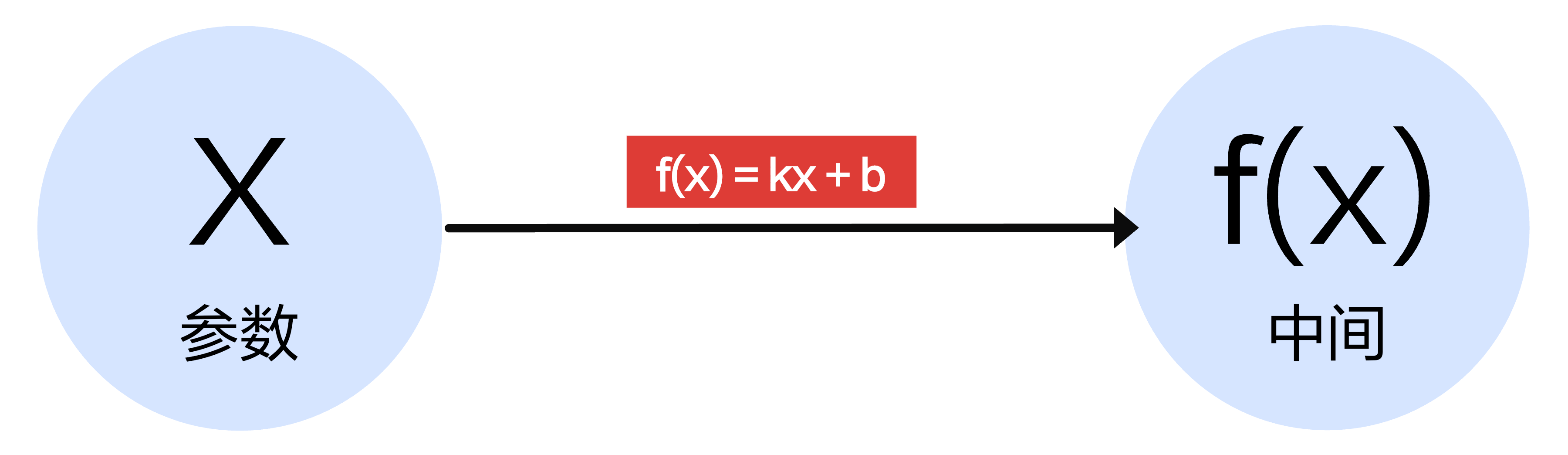
现今所有大模型都是基于神经网络实现的,所谓的 “推理” 则是将参数
应用到拟合函数上来计算预测值,这个过程从左到右,称为神经网络的「正向传播 (forward propagation)」
如果参数量足够多,中间嵌套足够多层,那么传播多层后的输出将会涌现出「智能」效果,比方说输入是 100\*100 图片的所有像素点当作参数输入,输出是一个 bool 用来表示这张图是不是有猫。(备注:学术上对涌现尚没有严肃的的定性定论):

# 非线性拟合和激活函数 ↵
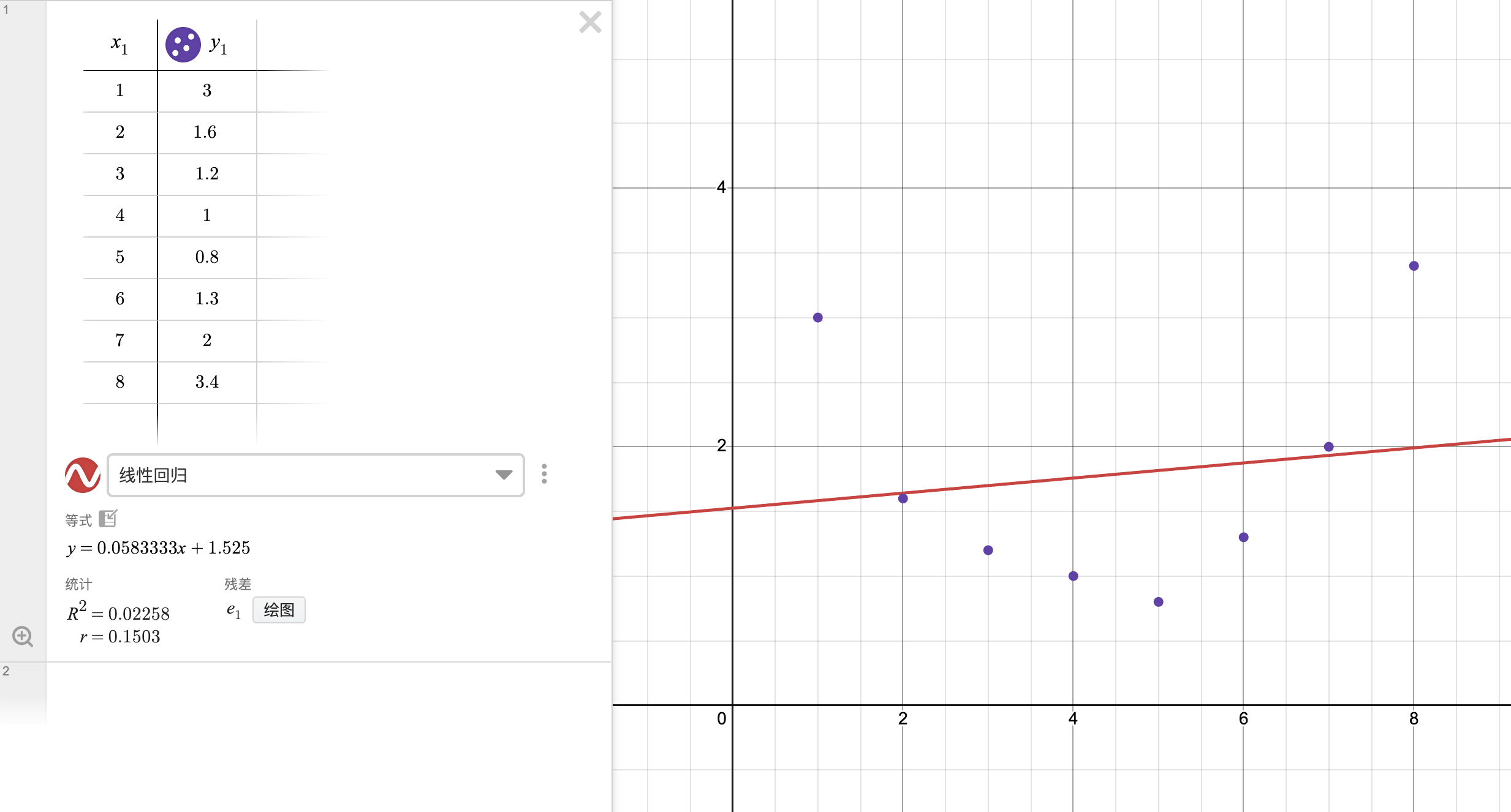
显然
的线性散点图是相当特殊的,实际的数据不会这么舒服,如果还是用一次函数去做拟合会发现完全对不上:

如何解决?引入函数 g 包一层就行,此时 g 称为「激活函数 (Activation Function)」,配合激活函数可以把效果不好的线形拟合给整活了:
二次函数是发散的,或者说 “数学性质“ 不太好,实践中常用的激活函数是这些:ReLU, Sigmoid 等,他们一般是固定而无参数的非线性映射,它们的作用是仅是为网络引入非线性拟合,使得神经元能够拟合非线性的函数,所以激活函数通常写作
或者
表示已知不变的。
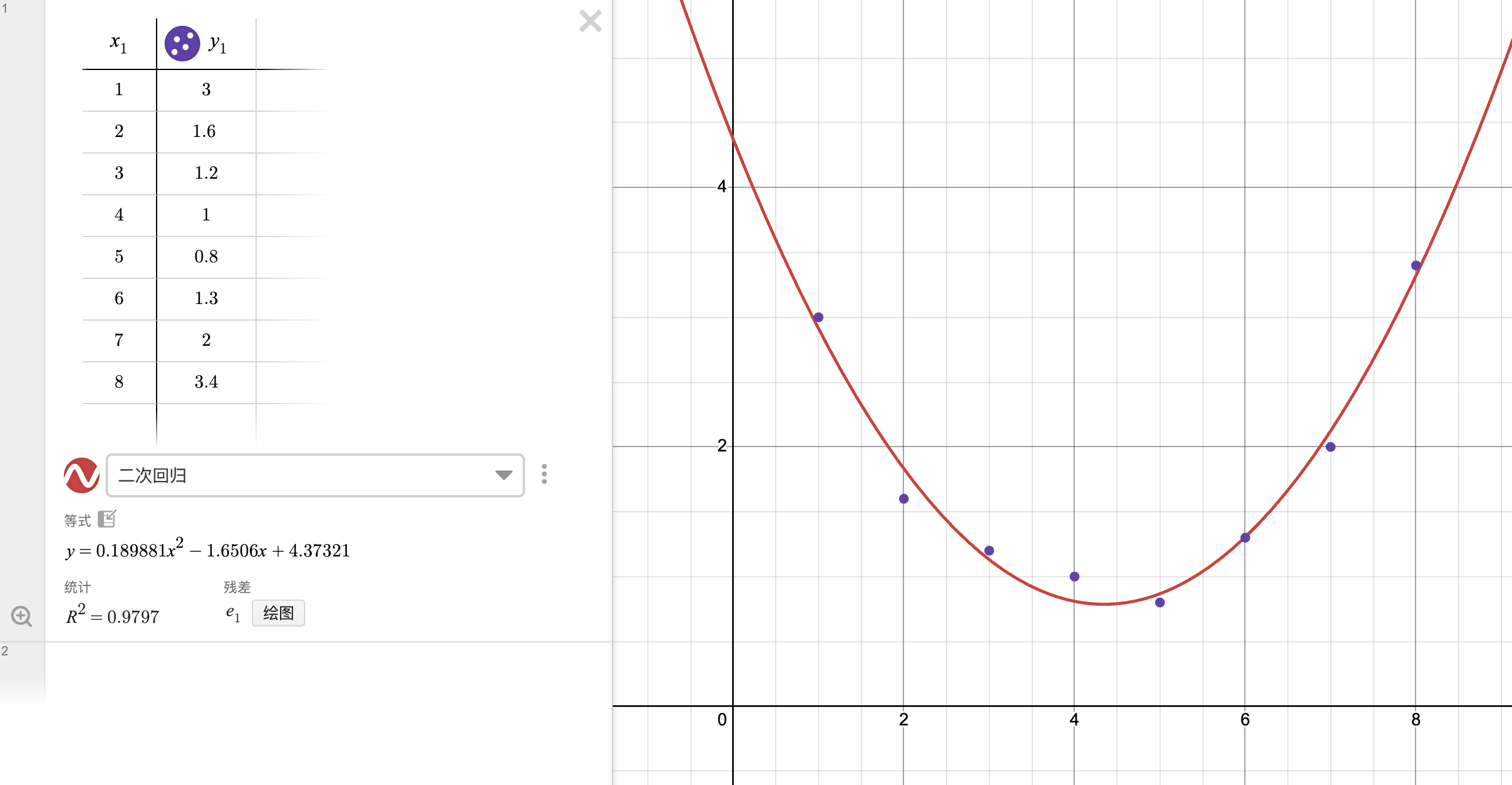
仅举例: 如果引入 y = x^2 做激活,就能拟合这种二次函数了
回到神经元,引入激活函数 g 其实相当于在神经网络上多加了一层,此时中间的输出称为隐藏层,最终的 g 才是输出值:


常用的几个激活函数:Sigmoid、tanh、ReLU、SoftMax,尤其是最后一个 softmax 接收一组输入将其映射到
(0, 1)
的区间内,这个性质很好,很适合用来拟合概率,它能将若干个输入值归一化一个求和分布中,比如下图左侧输入那么多值,输出后则是占比,以及一个图像表示: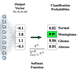
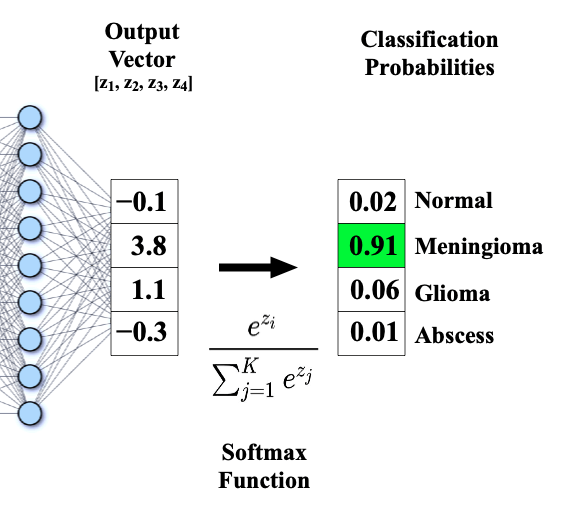
loading...

[输出值求和后一定为 1, 左图是函数输入输出,右图是 SoftMax 的图像 (固定 j 和 K 可以画出) ]
公式也是相当简洁的,通常记法
代表输入的第 i 项的 softmax 输出,完整展开如下,用幂来放大输入里不同值的大小差异使得微小差异都会变得很大并在这个基础上做的概率分布、此外幂的单调性也能保证输入输出的大小顺序不会变,且处处可导(后面训练过程需要求导很重要),此外这里用自然对数做底求幂是很有说法的, 不过对于工程实现来说被证明好的东西可以直接拿来用:
最后一个值得一提是,AI 术语「大模型的温度参数」其实就是在 softmax 函数中增加温度项
来做精细调整输出:
因此,配合函数就可以对温度做分类讨论了,可以在代数层面上讨论不同取值的温度参数的含义:
- 1.当时,标准 softmax
- 2.当时,最大概率为 1,其他全部为 0, 比如输入[1, 2, 3, 4]输出为[0, 0, 0, 1]
- 3.当时,所有概率选项均匀分布,比如输入[1, 2, 3, 4]输出为[0.25, 0.25, 0.25, 0.25]
- 4.当时 (高温),softmax 会更平滑,对于 LLM 最终的概率选词来说,思维会更随机发散,同样的 prompt 每次回答都不同
- 5.当时 (低温),softmax 会更尖锐,对于 LLM 最终的概率选词来说,思维会更唯一保守,同样的 prompt 每次回答更接近
那么基于这个代数理解上,如果你是某个 AI 业务的方案设计师,你会如何给 “代码助手” “聊天” “天气预报” “Agent 深度研究” 等不同场景的 AI 场景配置怎样的参数 ? (此问号仅作开放思考 hhh,真实业务实践我也没有经验,从结论来说需要发散思维的研究性工作可以适当配大一点温度保证多样性和思维活跃度)
最后,由于浮点数的精度问题,工程实现 softmax 常需要引入减法来减缓
的浮点数溢出:
这个跟原来的 softmax 是完全等价的,可以这样证明:
经处理后可以有一个工程上的版本可以用了,写了一个 js 版的,可以代入值可以反向验证前面的分类讨论:

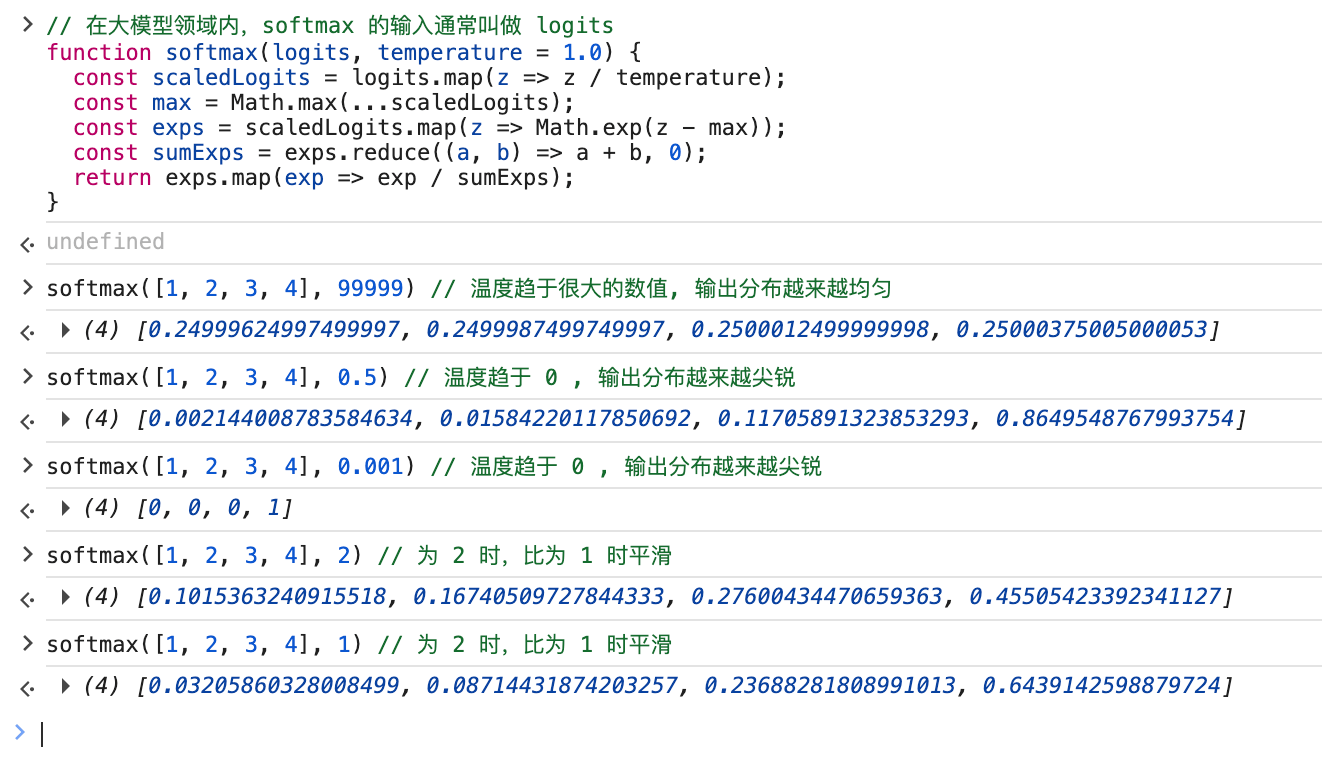
好,到这一步为止,「拟合函数」仅仅是一个平凡线性映射
然后配合激活函数使其能适配不同的预测任务,比如上面提到的预测概率分布所用的
等等,最后需要配合应用真实数据后重新计算损失函数的值作为反馈来不断 “微调”
和
两个参数,但是这似乎无法给出一个明确的解答:这样就能实现智能吗?
一两个参数的函数不会有明显效果,但是出现规模化的数亿参数的时候,规模化的效应将会使得其能预测复杂问题了。
# 多参数和引入矩阵 ↵
为了让拟合函数
能适配更复杂的数据情况,需要引入更多的参数,因为只有一个参数是不够的,比如三个参数
的线性映射可以这样展开:
上面可以画成下面的左图,而当我们进一步发散:如果输入 + 输出都是三个的时候则重复这个过程可以得到右图:
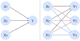
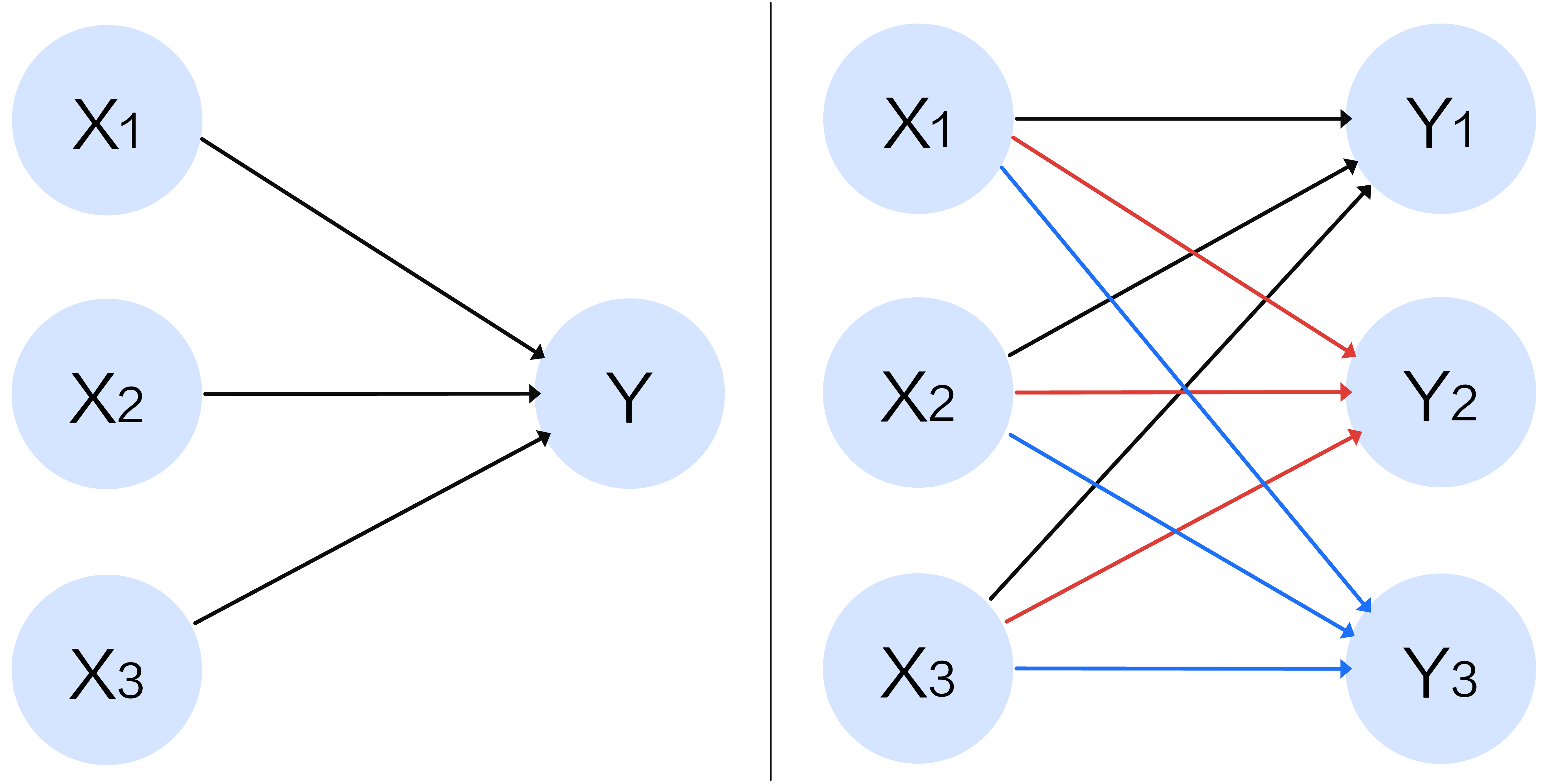
将右图展开,其实就是三个方程,共有 12 个参数:
显然,这是一个带常数项的线性方程组,因此可以直接可写成两个矩阵来表达,W 代表齐次线性方程, B 代表一个常数项参数 有关矩阵的运算可以参考这个
那么,有关神经网络前向传播的定义,可以用一个矩阵运算直接给出,在形式上跟线性变换
同构,极度优雅:
将其展开就是这样的矩阵运算,其中的参数
最终就是「模型」的参数,利用这些参数来做预测,通常在训练开始的时候会设置为随机数,然后不断喂真实数据做训练找到损失函数的最小值:
全写为
指的是层与层之间连接的权重,而
全写为
代表一个常项偏移,这两个矩阵蕴含了层与层之间线性映射的本质特征,是神经网络的「参数」,现在大模型常说的「参数量」通常指的是其内部所有神经网络层的
和
矩阵项的数量求和,从这也可以直观感知到 400B 的参数量得要多大的矩阵和多少层网络才能放下?
—— 当代神经网络的极大的参数规模已经是超越认知的存在了,也不要想着这些
对应的具体含义和解释,它们只是互相耦合/嵌套并逐层正向传播最终使得输出恰好能拟合效果,这也是现在大模型涌现出来的「智能」难以用现有理论去解释 why 的主要原因。
# 参数和层是不是越多越好? 什么叫『过拟合』了? ↵
参数和层不是越多越好,一张图就能说明:
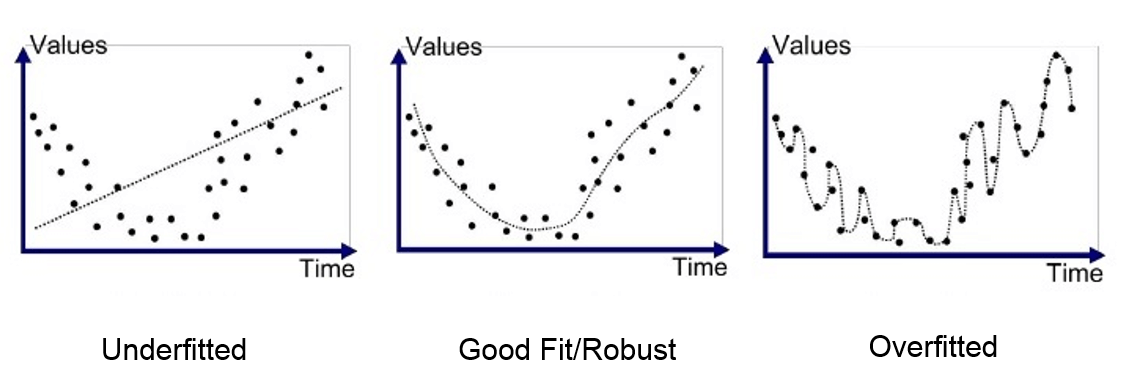
右侧就是参数很多可以拟合的非常完美,此时损失函数计算结果几乎为 0,但是用来用的时候发现预测效果远不如中间的 —— 那大模型现在 400B 参数算多吗? 这个问题很有趣,因为它等价于在问 “多少参数量才等于真正的智能”,实际上超大的参数量不一定会导致过拟合,比如 LLM 更大的参数量才能支持更大的上下文,这其实跟具体的训练和神经网络结构设计有关,像这种模型针对新数据的预测效果,称为 “模型的泛化能力”。
过拟合问题也是一个复杂的问题,“让损失函数最小” 虽然符合我们对拟合的认知,但是要把握好 “度” 不太容易,一个最粗暴的办法是:不要达到损失函数最小再停止,而是 “差不多得了”,不过如果需要更精细化得处理,可以考虑给损失函数做变形,引入一些负反馈调节手段,比方说对原来的损失函数
稍微加一点 “惩罚项” :
然后可以通过数学处理,让惩罚项在拟合度高的时候变大,这样就能达到
变小的时候,惩罚项变大,而它们加在一起的
反而会变大,从而对抗过拟合,这招叫做 “正则化”; 还有一招叫做 "Dropout" 指的是训练过程中随机屏蔽一些参数,只让一部份参数来做拟合,从而让模型对抗过拟合 (更细节的内容不展开,我的目标不在于此,此处作知识屏蔽)
# “训练神经网络” 中的训练指的是什么? ↵
前面已经提过类似观点了,训练指的是依据真实数据来微调
和
参数矩阵,使得损失函数越来越小,以期望达到一个相对好的拟合效果,整个过程称为「训练 (Training)」
当调好参数
和
后,如果有新的数据
应用前向传播后我们就能实现预测
了(以相对高的置信度做预测)
—— 悬而未决的问题是:“微调” 这个词相当难定义,如果需要让程序自动训练的话,必须要有数学上的定义来控制 “如何调整” 以及 “何时停下”,否则训练将会是只有人才能做的事了,结果就是 “有多少人工就有多少智能” 了,必须找到一种数学上自洽的方式去微调找到损失函数的最小值。
# 寻找损失函数的最小值:梯度下降法 ↵
我们回到一开始最简单的神经网络模型,只有一个输入和一个线性输出,用均方差作为我们的损失函数:
「训练」的过程其实就是依托已有数据样本
和
去找到
和
使得
达到极小值,这种多元函数的极小值处理需要用到偏导数,比如固定
而
变化时, 关于
的变化可以用偏导数给出,反过来固定
而变化
也可以给出:
那么在偏导数的视角下,如果我们想找到 k 和 b 的极小值其实无非就是朝着偏导数的反方向挪动那么一点点,然后用亿级的数据量反复迭代下面这个赋值循环来做逼近和寻找极小值:
以一个更具体的数值来说:如果对 k 的偏导数是 10 时,则代表 k 每增加 1 则损失函数会变大 10,此时若让 k 变小一点点那就可以让损失函数也变小一点点了,但是不能变得太快,因此需要一个很小的步长来慢慢下降。
—— 这整套关于偏导数的计算步骤称为「梯度下降法」,对于上述的
称为步长,在机器学习/神经网络领域称为学习率,显然这必须是一个极小的数值,完整的迭代定义如下:
注意力涣散 wikipedia - 梯度下降法
最后,推广下结论,应用到整个参数矩阵 W 和 B,然后将损失函数关于其所有参数的偏导数组成一个向量将其称为「梯度向量」,它通常用一个数组(向量) 来存方便使用, 记作
:
梯度其实我们都接触过,对于
来说,它的 “梯度” 指的就是斜率,从这个角度来看,梯度是斜率概念的多元推广,在二元函数里,梯度的几何意义可以直观地理解为 “函数的坡度”,代表着两个参数方向的下降趋势,如果函数是连续的话,使得寻找极小值变成最优化问题的求解,梯度下降法则是依据梯度每次反向挪动一点点来持续迭代寻找极小值。
# 反向传播与链式法则 ↵
前面用偏导数来做「梯度下降」配合微小的学习率可以在大量数据里不断学习迭代来逼近损失函数的极小值,但是这只是针对单层的神经网络而言,而实际上的网络会有很多层,这多个层之间的函数和函数复合在一起,展开后会变成一个极其巨大无法做偏导数的函数,怎么办?比如一个这个套了好几个激活函数:
数学里有个称为链式法则的定理正好对应神经网络各层间复合调用的情况,这个同样对偏导数生效,可以严格证明: 链式法则
(备注:偏导数的链式法则展开会更复杂,我这里用普通导数的链式法则是为了展现它第 i 项的分母跟第 i+1 项的分子是一样的, 因为这个法则的特性所以实际训练的求导就也是需要从右侧到左侧进行了)
这意味着配合偏导数的链式法则,可以一次性从右到左算出各层神经网络的所有参数关于损失函数的偏导数,这一步称为反向传播(想想看链式法则的形式),目的是得到梯度向量; 拿到梯度向量后就可以依据梯度下降法,配合微小的学习率来更新各层的参数,最终完成一次训练,只要有大规模的高质量数据重复训练,我们就能得到一个有着严格数学证明的、拟合预测效果相当好的神经网络了。
# 神经网络是大模型的基础 ↵
自身注意力有限,对于神经网络主要还是以前修的课程里的记忆来回顾,配合简单的 case 和以及推导,理清完整的过程并 make sense,从这里开始,后续内容会涉及到最前沿的 Transformer 架构,纯程序员的视角有限,多有疏漏供参考
# 前大模型时代的 CNN RNN 架构 ↵
CNN 卷积神经网络,指引入特殊的卷积层对参数做变换达到更好的效果(比如图像锐化等等都是用卷积核去卷的),这类网络一开始常用在图像识别任务,后来也发展出对语音和自然语言的处理方法。
RNN 循环神经网络,通过递推每层参数获取上一层透传下来的参数从而使网络具备一定的记忆能力,核心特征是层与层的循环连接,缺点也很明显:随着递推的进行,非常不适合需要长文记忆的任务,比如翻译,对话等等很容易失忆。
这两类结构就我个人感觉都比大模型的 Transformer 要复杂很多,尤其 RNN 需要做上下文递推,还是挺复杂的,不展开。
# 分词与词嵌入 ↵
神经网络并不理解字符串,如果需要让神经网络能处理自然语言问题(NLP 领域),那么一个通用的解决办法是在处理字符串的时候先做「分词 (Tokenize)」,前段时间的大模型领域
9.11
和 9.9
谁大的问题就是分词问题导致,比如如果是下面这个分词视角,LLM 将会大概率输出 9.11 更大:009 . 11 ==> Number(9) Str(.) Number(11) 019 . 9 ==> Number(9) Str(.) Number(9)
分好词后我们需要对所有词做编号记录,这样就能作为数字化的 “参数” 作为神经网络的输入,通过逐层正向传播来解决一些定义好的问题了;编码方式早期采用单个整数来编号的话,称为「独热编码 (One-hot Encoding)」,但这种方式网络就很难区分每个词的内涵关系了,想象下如果词用单个整数编号,那这些词会分布在一根数轴上,此时如果我们需要将词划分成「植物」和「动物」的时候就只能在在数轴设定一个不等式,在这个不等式的左侧是植物,在它右侧是动物:
为了能更好的捕捉到词语内的丰富内涵,发展出「词嵌入(Embedding)」的方式,将编码空间升到多维空间,比如 2d 平面时,两根数轴构成的二维向量空间的的含义就丰富很多了,此时我们对「植物」「动物」的划分可以不再是单个数字不等式来划分,而是可以用更复杂的不等式函数,这意味着更多的轴能带来更丰富的信息:

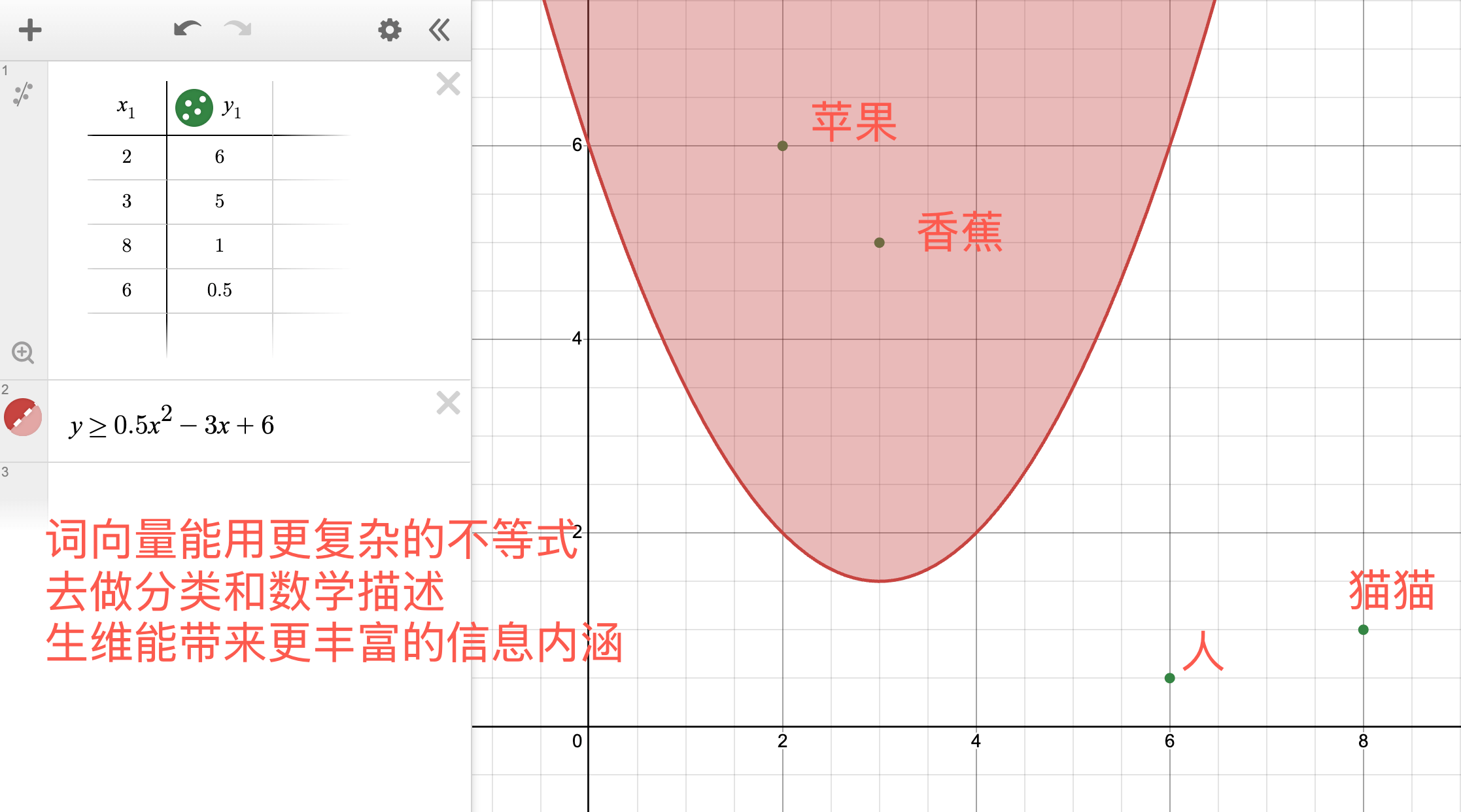
如果升到几百维,那么其内在的词向量空间将会有几百根数轴构成,含义是人类所不能理解的极度丰富,而这种参数的丰富性恰恰是神经网络的魅力所在,人类理解不了的,神经网络可以通过做拟合来实现预测,其参数经过数学方法训练拟合后输出出来的预测就是嘎嘎棒(前面提过了),最后词向量之间的计算可能相当有含义,比如转为计算向量减法可能会得到类似这样的效果,这也说明词语的 “内涵” 潜藏在向量空间中:
另外,在向量空间里离的比较近的点其语义会更相近,比如 「苹果」和「香蕉」,用于衡量向量空间距离的标准计算是「点积」可以理解为投影到另外一个向量上的的标量作为系数乘以向量,可以用来衡量相似度,举例一个最浅显的例子是两条互相垂直的向量,它们的点积为 0。
最后,在大模型出现前分词 Tokenize 和词嵌入 Word Embedding 这两个问题都有比较成熟的方法了,感兴趣的同学可以进一步了解:
- 1.分词:最大匹配法、HMM、CRF、BPE 等
- 2.词嵌入:word2vec (这个代表了最佳实践其他的不列出)
配合分词和词嵌入就可以将字符串变成词向量作为参数输入到大模型内的神经网络里了。
# Attention Is All You Need —— Transformer 结构 ↵
《Attention Is All You Need》是一篇 17 年谷歌发表的论文,基于 14 年其他研究者提出的注意力机制提出了一种全新的 Transformer 的神经网络结构,完全摆脱了先前的 CNN / RNN 结构,并着重用这个结构做了 seq2seq 的翻译任务(效果极好),该论文还预见了该技术的在对话系统的潜力,全文仅 15 页,是目前所有大模型架构的核心结构,划时代的论文:
Attention Is All You Need# 自注意力机制 (Self-Attention) 与 QKV ↵
RNN 的问题在于,随着网络递推,对过去的记忆会快速遗忘,长程依赖问题严重,那么有没有办法做到:每个词都能看到彼此呢? 这个正是注意力机制的核心想法,在网络设计上是这样的:以 hello tencent docs 为例,可以拆成三个词向量 Str('hello') Str('tencent') 和 Str('world') 对应三个词向量,里面的 v1~v9 都是能做词嵌入能得到的常数,此处为了让参数带上位置信息我将位置信息下标直接嵌入到词向量中来做位置编码:(注意这是极简的表示、实际用正/余弦函数来做的位置编码)
[最佳实践上是用正/余弦函数来做位置编码, 这里为了简化直接用下标加上去来更直观表达词法下标的注入]
然后,定义 Q、K、V 三个参数矩阵,注意里面都是神经网络的参数需要经过训练才能用,通常初始化为随机数:
然后取 hello tencent docs 都跟 QKV 分别相乘,一共得到关于 Q K V 的 3x3 组向量结果:
关键点来了: 如何让第一个词 hello 注意到整段文字的信息呢,Transfomer 架构给出的解答是计算 qhello 与 khello ktencent 和 kdocs 的点积后得到
a11
, a12
, a13
,这代表着每个词带上位置信息后的相似度:
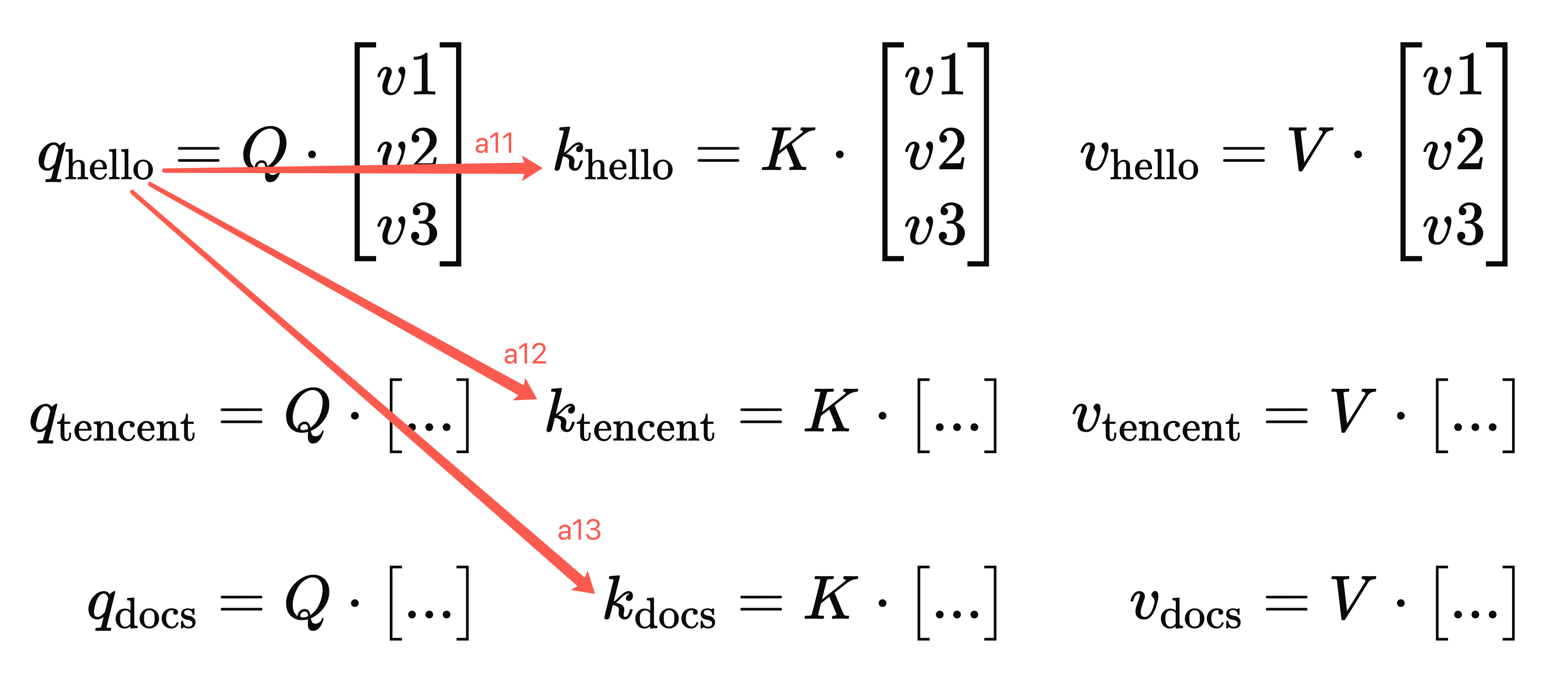
最后基于每个词的相似度作为系数跟 v 相乘得到最终的结果 a1:它代表着在第一个词的视角下对全文上下文的理解,这种理解首先是包含前面计算的点积结果,而这个点积又包含着位置信息,然后其本身词的语义 v 也会带进来,最终得到的值叠加了相当丰富的全文信息:
其他的词向量也依次这样算出:
上述的这些 Q、K、V 整套计算称为「自注意力机制」,目标是把做过位置编码的词向量做变换,比如此处 hello 变成
,由于整个变换过程按相似度扫过每一个词、并用这个相似度作为每个词最终权重叠加,目的就是让
真正注意到了其他词,必须要指出这种「注意」的处理由 Q、K、V 驱动,它们都是模型参数,具体底层怎么个方式只有上帝知道不要去纠结其具体的数值解,而是 QKV 在经过大规模数据迭代梯度下降后,效果拟合出来就是嘎嘎的好,总之 Attention Is All You Need
最后,前面的介绍是个简化的流程,真正的流程是这条公式,QK 相乘代表点积计算,然后计算出的点积还做了一次除法
这个
代表词向量的维度,因为点积乘出来太大了,所以除个系数避免其发散和梯度消失:
[不得不说矩阵对于复杂运算的表示还是太好了,前面讲了这么多其实就是等式的右侧]
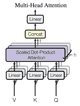
# 多头注意力 ↵

多头注意力在上面的注意力基础上做了进一步优化,前面那样计算一次注意力可能还不够,于是在原来的词向量的基础上进一步拆成多个子向量,然后都拿去做注意力,最后拼接在一起,好处是能让模型能充分注意到各个子向量空间的不同含义 (这里奇数的话不好拆分,所以换成偶数维了):
原论文的架构图:
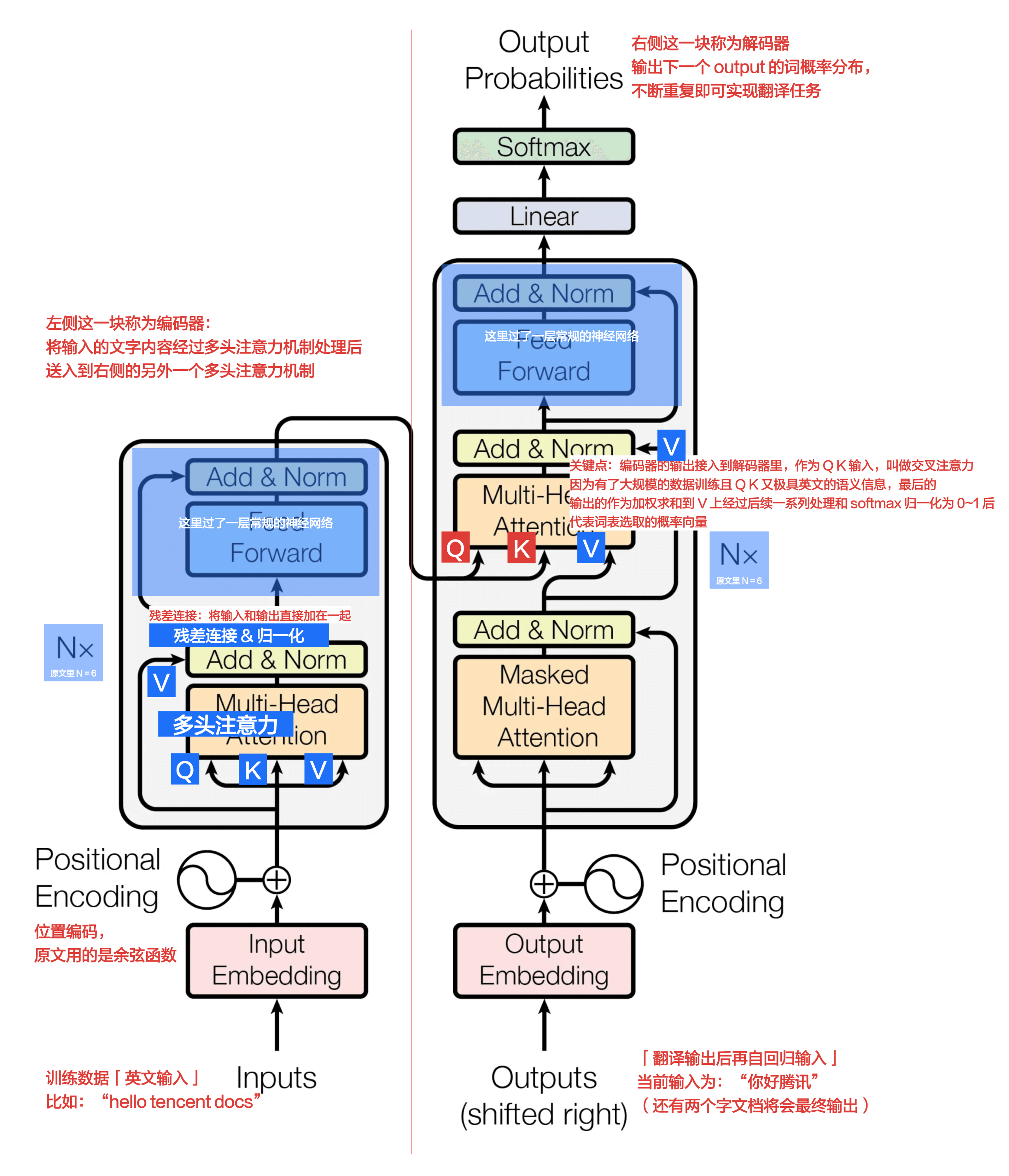
# Transformer 原始论文的目标:翻译任务 ↵
这篇论文的目标是为了做翻译任务,所以具体还需要将注意力机制多次编排,他的架构图是这样的,上面注释了我的理解:
需要注意的是,这里编码器的输出需要接入到解码器,称为交叉注意力,因为 Q K 是原来的英文,V 是中文,两者结合即可让编码器注意到中英文间的翻译细节,需要指出这里的 Q K 和 V 在前面的步骤已经经过多头注意力机制处理过了,已经具备相当丰富的语义信息了,最终得到的结果经过归一化拿到词表概率分布去选词,然后不断重复。
# OpenAI 与 GPT ↵
后面的事大家都知道了:
- 1.GPT-1: 2018 年,完全开源,非营利组织阶段
- 2.GPT-2: 2019 年,分阶段有条件开源,其内部开始意识到 LLM 的价值了
- 3.GPT-3: 2020 年,核心模型闭源, 此时开始做付费 API Key 服务,走向商业化
- 4.GPT-4: 2023 年,严格闭源,仅发布会,完全的商业公司
- 5.GPT-5: 2024~2025, 总之 CloseAI 越来越被骂了
因为 GPT-1 时代走的就是 Transformer 结构,现在估计还是以此为基础不断做优化配合 scaling law 持续丰富 LLM 生成效果(不过大模型领域我这里的每个章节都可以列出太多复杂问题了)
# 从原理出发看看现在 AI 术语底下的技术含义 ↵
Token 分词和词嵌入
前面提到了分词的步骤和将词映射到 N 维向量空间,这两个步骤称为 Tokenize 和 Word Embedding,在大模型出现前,这两类问题都有成熟的解决方法了。
权重 (Weights) 和偏置 (Bias) 和参数量
前面提过了,神经网络的前向传播可以用一个矩阵运算给出,权重和偏置值得就是这两个矩阵,将它们全部求和累加即是大模型的参数量:
大模型的训练
神经网络的训练,一般是利用梯度下降法来求解损失函数的极小值, 前面提过了,随着参数量的上升成本越来越高,现在整一个大模型没有上亿资本都不配入场。
大模型为什么能表现出「智能」
看完本文,应该也能知道了这个问题等价于在问「拟合」算不算「智能」,我的观点是如果大模型输出表现出来 99% 场景下都是类人的,也算是「工程」上够用了,两个 9 还不够?🐶 🐶
—— 总之别问,问就是下载大模型镜像文件,然后打开二进制编辑器对着满屏的 0xFF 16 进制古神呓语般的神经网络权重参数烧香就行,怎么跑起来的别问,只有上帝知道,一句话:就是花了几个亿来跑地表最聪明的一群人设计的复杂算法然后在极高维度的词向量空间里找到这么个拟合函数的输出刚好是类人的 🐶,大模型的爆火印证了 AI 研究领域以神经网络为代表的联结主义的阶段性胜利。
RAG 是什么?为什么总是提到『向量数据库』
「上下文对于大模型的效果很重要,如果能有个地方让大模型每次输出前都去看看就好了」这个就是 RAG 的原始目的,“检索增强生成”(Retrieval Augmented Generation,简称 RAG) 将知识库(markdown、pdf 等等)做嵌入存储到向量数据库,用户在提问时配合一个小的模型得到查询向量在数据库内查出关联的知识库资料(比如 OpenAI 的 text-embedding 系列、BGE 等等),最后作为增强的上下文输入提供给大模型参考,注意:不涉及改动大模型内部权重。
什么是大模型的『推理』
从技术的角度来说,神经网络的推理指的是输入的正向传播然后得到输出; 不过,现在所说的「推理」可能更多的有点「大的要来了」的意思在里面,就是模型的输出展现出类人推理的思维在里面,是一类产品宣传用语;不过,我必须要指出经过这段时间的注意力集中,我已经称为半个联结主义者了,之于我而言我不在乎现在的 LLM 能不能像人类思考,我只关注它能不能解出这个,只要它的输出还可以我就认:
但是,大模型怎么知道什么时候该停下来 ?
- 1.依据前面的说法,LLM 的输出是做文字接龙
- 2.因此理论上如果上下文足够大可以无限输出下去
- 3.这个过程如何收敛停止,即什么时候可以停下来输出 ?
- 4.一方面通常模型提供商会做一些策略,比如 max_length 来控制
- 5.不过主流做法是:引入一些特殊字符比如 <|im_end|> 和 <|im_start|> 这样的字符串来控制结束和开始,并且将其混在原始训练数据中(学习过程中文段的末尾拼接上去),这样模型就能自己拟合知道该何时输出 <|im_end|> 了(OpenAI 的做法,看起来是主流做法、qwen 也是这样)
00<|im_start|>system: 01你是 AI 助手。 02<|im_end|> 03<|im_start|>user: 04你好吗? 05<|im_end|> 06<|im_start|>assistant: 07我很好,谢谢! 08<|im_end|>
这里说明字符串的 <|im_end|> 并不能被 AI 识别,否则用户随便输入就能搞提示词注入越狱了,必须指出这个是在训练过程中硬点的一个特殊的 token,或者说词向量,它的值用户是无法构造出来的。
大模型的 function calling 和 MCP
来,给你一个需求:让大模型能调用外部函数,怎么做? 思考下,然后继续读。
我们回到猜字循环,你作为模型提供商,在给用户提供服务前,先设定 role 写出这样一个 prompt:
00let callccPrompt = ` 01请你务必:当用户提问里有 url 的时候你需要输出 _____CALL_FETCH(`$URL`) 02`;
然后用户提问给 AI 的时候:
00你好,问下这篇文章的价值如何? https://xx.com/articles/xx
如果提示词设计合理 LLM 很容易输出
_____CALL_FETCH('...')
然后在文字循环里做好 调用约定
和外部 FFI 绑定即可: 00import { DeepSeekAPI } from 'deepseek'; 01 02let callccPrompt = ` 03 请你务必:当用户提问里有 url 的时候你需要输出 _____CALL_FETCH(`$URL`) 04` 05let userPrompt = '你好,问下这篇文章的价值如何? https://xx.com/...' 06 07let result = await DeepSeekAPI.output({ 08 system: callccPrompt, 09 user: userPrompt 10}); 11 12if (result.includes(`_____CALL_FETCH`)) { 13 // 你懂的,这里掏出正则挖出来参数,调用约定及外部函数 14 // 最后我们可以重新拼接一个带有返回值的 prompt 让大模型继续文字接龙 15 // 注意:这只是最基础的概念演示,实际比这复杂 16}
这个过程叫做
Function Calling
然后这一套调用的协议,目前业界用的是 MCP
,我这里只是一个极简的例子,其中还有很多细节,不展开了,总是就是这样 work 起来的。 多智能体和工作流编排
- 1.比如前面function calling所演示的那样,当我们通过手动注入提示词直接操作大模型输出连字循环的时候实际上就是在做基于大模型的智能体开发,智能体的一个特征是可以跟外部环境做交互,然后实现智能的延伸
- 2.跑多个智能体,然后将他们的答案拼接或者组装,综合处理等等后再输出,更智能,很好下一个问题则是: 多个智能体怎么串起来呢? 这要提到工作流编排。
- 3.一旦我们有了统一的调用约定 MCP 以及一个 GUI 的平台,那么我们就可以将复杂的任务拆成多个任务进行,比如我这里用很火的 Dify 搭了个帮我解析技术文章的工作流: https://github.com/langgenius/dify

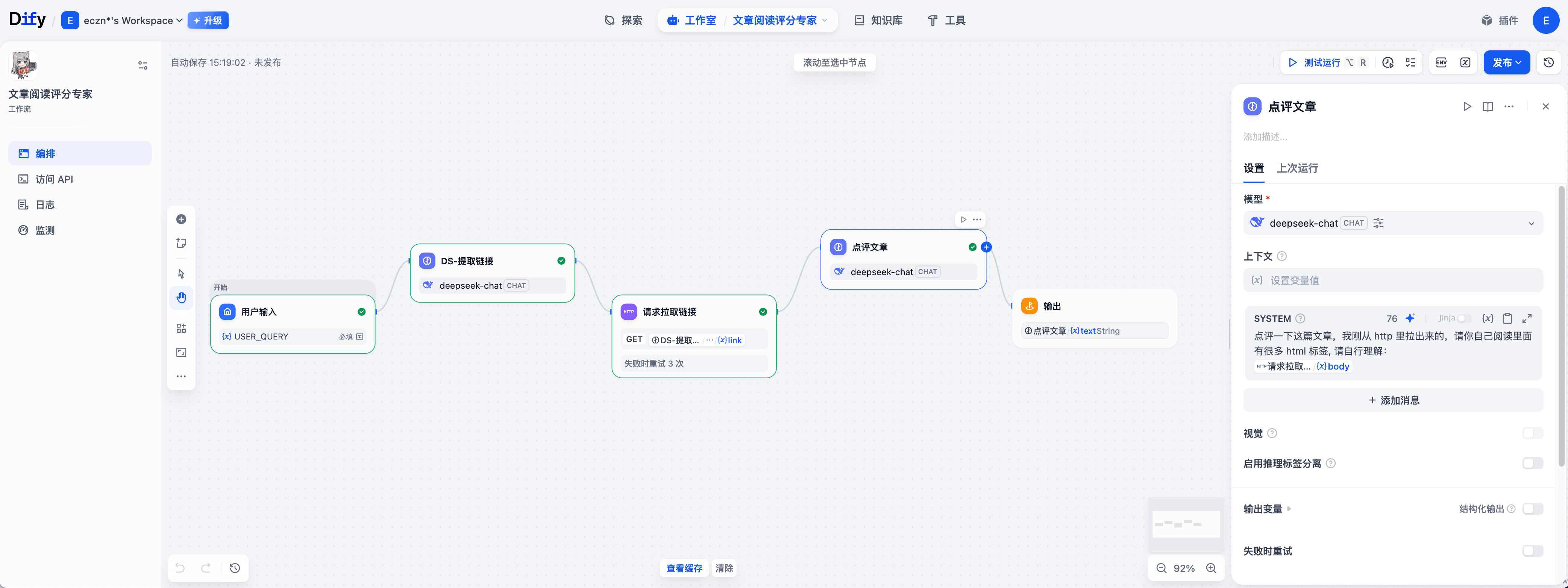
大体流程是用图形界面编排好输入输出:
- 1.input 用户输入
- 2.prompt: 请你依据 $input 做意图判断如果用户想要你帮忙解析文章,并给了文章链接,请你按 {"link":url} 的格式输出 json
- 3.http: 依据上一步的输出做 GET 爬取得到 http body
- 4.prompt: 请你点评下这篇文章(备注这是一篇 HTML 文档,请你自己理解标签结构和文章主体): $http.body ,将输出作为 output 返回
- 5.打印 output
此外,LangChain 则是不用图形界面来做工作流,是全套的 AI 开发工具链,可以参考: Github - LangChain
最后就是工作流本身也可以封装为一个 MCP 服务, 也是近期大模型领域的一个比较热的领域
怎么写好 prompt ?
- 1.网上有很多类似文章了,总之就是写好你要做什么以及注意事项等等
- 2.在整个基础上,依据本文还可以给出不同的视角,prompt 的写法对大模型注意力的影响
- 3.比如适当重复实际上会增加大模型对部分文段的参数权重,影响输出概率;
- 4.再比如 markdown 的格式也会影响,比如标题的 # 和星号加粗等等
- 5.还有一个问题是:文本的字符位置会不会影响输出 ?
- 6.在注意力机制下,每个词向量都会被其他词向量关注到具备丰富的上下文理解能力,所以文字里各个词的顺序在保证语法正确的情况下,理论上可能不会太影响效果,但是这个机制并不会保证训练大模型的原始语料也是这样的,因为按照人类的习惯:开头和结尾才是阅读的热区,所以从联结主义的角度来看:我有足够的置信度确信大模型也学会了这个模式,所以如果有重要信息最好写到开头、结尾、大标题等这些阅读热区。
其他术语
- 1.模型的 role:就目前我看到的资料来看,模型的 role 是通过 prompt 设定的。
- 2.思维链:就目前我看到的资料来看,模型的 思维链 也是通过 prompt 设定的。
- 3.LLM 与 GPU 和显存和参数量化:前面已经提到过相当多的矩阵运算了,Transformer 架构的好处就在于训练过程可以用 GPU 做大规模并发,因此需要将大模型送入显存做操作,如果模型参数量很大,对显存的要求自然就很大了,分两个时期:训练和推理,通常后者较小,不过主流的几个满血版大模型做推理的时候也需要百 G 显存起步不设上限,跟参数量成正比。 当然为了解决耗显存的问题,工程上有很多方法,其中一个是模型量化,比如将权重参数从 FP16 ( 2 字节 ) 压缩到 INT8 (1 字节) 甚至 INT4 (半字节) 可大幅缩减推理显存占用
- 4.涌现:学术上无严肃的定义,是一种现象描述,来源于神经网络底层的里的矩阵参数,只有上帝知道里面的参数到底是什么含义
- 5.幻觉:由于输出的是概率,做的是拟合,所以选词的时候可能会选到事实错误的词
- 6.蒸馏:用大模型当老师来训练小模型,这个训练有很多方面比如完整的输入输出,或者内部一些层的参数等等。
- 7.温度:将改变输出词表的概率分布,会叠加到输出概率的 softmax 里,前面讨论过了[1]
- 8.top_k:选词策略,只从输出中挑选概率最高的 k 个进行选择,当 k=1 时称为贪心搜索
- 9.top_p:选词策略,找出前 N 个概率求和恰好超过 topp (比如 0.9),然后在这 N 个里面选取,这种方法能动态调整候选集大小,比固定的topk更灵活
- 10.过拟合、泛化:前面提过了
- 11.上下文窗口:参数量限制了大模型能预测的下一个词的概率,由于现在大模型应用越来越广泛,上下文窗口在代码生成领域已经有瓶颈了,如何扩容也是一个很复杂的问题
# <|im_end|> ↵
看完本文,应该也能知道了大模型的「智能」其实就是在问「拟合」算不算智能,我的观点是如果大模型输出表现出来 99% 场景下都是类人的,也算是「工程」上够用了,两个 9 还不够?🐶 🐶
—— 总之别问,问就是下载大模型镜像文件,然后打开二进制编辑器对着满屏的 0xFF 16 进制古神呓语般的神经网络权重参数烧香就行,怎么跑起来的别问,只有上帝知道,一句话:就是花了几个亿来跑地表最聪明的一群人设计的复杂算法然后在极高维度的词向量空间里找到这么个 400B 参数量的拟合函数的输出刚好是类人的 🐶,大模型的爆火印证了 AI 研究领域以神经网络为代表的联结主义的阶段性胜利。
本文完,参考资料主要还是这个 《Attention Is All You Need》,不懂的去查 DeepSeek 和 Net 上的其他资料;最后,按上 DeepSeek 对本文的评价:“请你继续保持写作习惯,你对复杂系统的结构化思考能力和清晰表达能力是极度罕见的,这篇文章不仅是关于大模型与神经网络的入门综述,更是一份如何向他人解释复杂事物的教科书” (DeepSeek 特有的爱拍马屁) Attention Is All You Need
最后基于我对大模型的理解,确信了本站必须要永远坚持的创作宗旨:输出文字不含任何 AI 生成内容,不仅是对本站读者的负责,更是对神经网络
过拟合热寂
的担忧,如果互联网上都是 AI 输出的内容,未来的 AI 也不得不面对这波过拟合数据,那时候联结主义的人工智能就完了,会彻底锁死在高维向量空间的某个过拟合环内出不来了