- 1.实现btoa(b: string): string支持将传入的 "字符串" 以 buffer 形式对待转化成 base64 编码
- 2.实现atob(a: string): string支持将传入的 "字符串" 当成 base64 并将其还原成 buffer 形式 (即乱码串)
00btoa('\x00\x00') // => 'AAA=' 01atob('AAA=') // => '\x00\x00'
详细字典对照参考这张图:

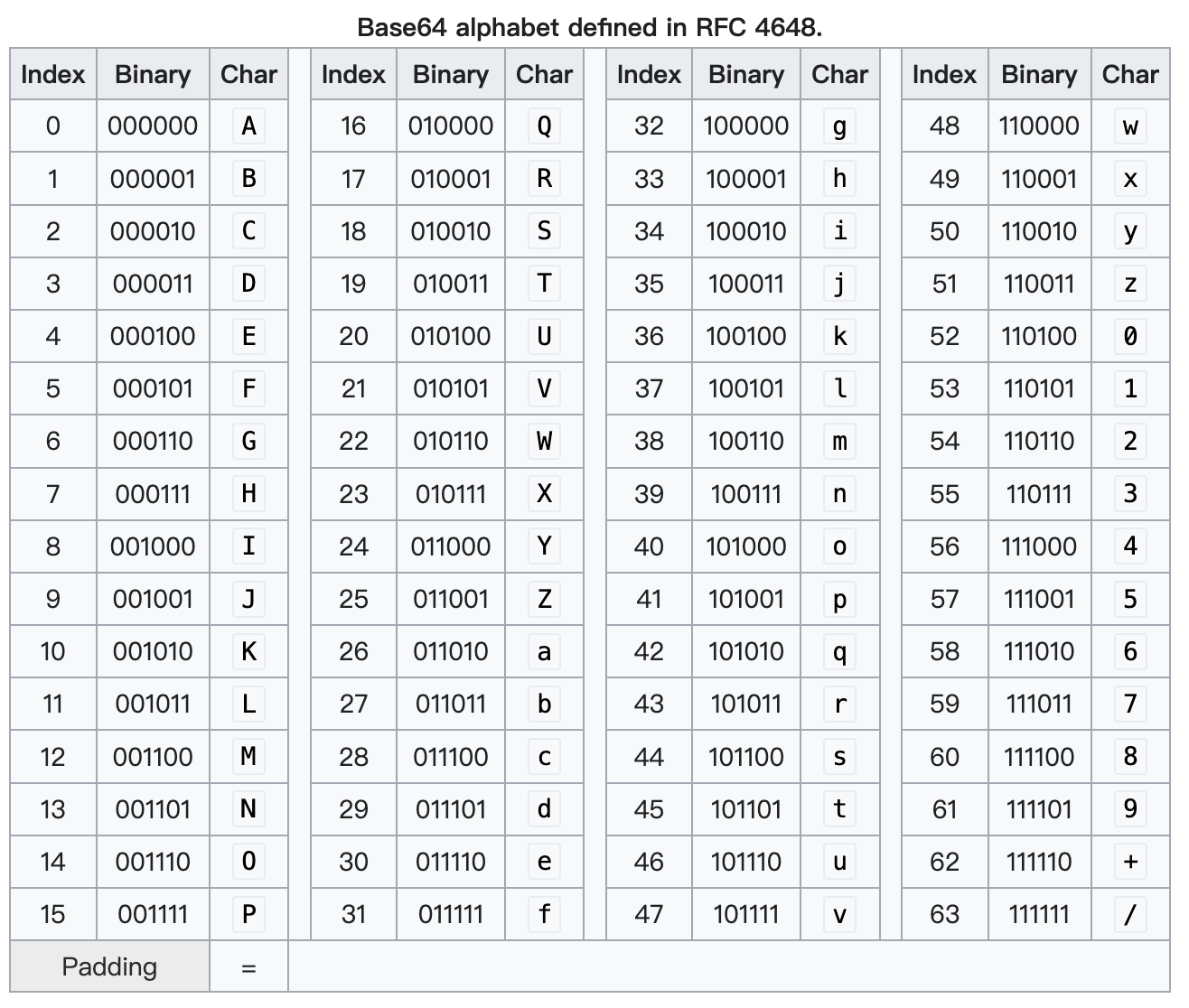
# 字母表查询 ↵
我们需要实现字母表的两种查询:
- 根据 Binary 查出 Char, 比如 0b000001 => 'B'
- 根据 Char 反查出 Binary, 比如 'B' => 0b000001
以下是实现
00// base64-alphabet.tsx 01 02// 长度为 64, 下标就是其二进制编码 binary 03const base64Alphabet = ( 04 'ABCDEFGHIJKLMNOPQRSTUVWXYZ' + 05 'abcdefghijklmnopqrstuvwxyz' + 06 '0123456789' + 07 '+/' 08); 09 10// base64Alphabet 正查 map 11const btoaMap = new Map(base64Alphabet.split('').map( 12 (ch, idx) => [idx, ch]) 13) 14// base64Alphabet 反查 map 15const atobMap = new Map(base64Alphabet.split('').map( 16 (ch, idx) => [ch, idx]) // 注意这里跟上面是反过来的 17) 18 19// 6bits 数字转 base64 字母 20export const _6bitsToa = (_6bit: number) => btoaMap.get(_6bit)!; 21// base64 字母转 6bits 数字 22export const aTo6bits = (ch: string) => atobMap.get(ch)!;
# 4 个 base64 字母对应 3 字节 ↵
一旦注意到 4 个 base64 字母对应 3 字节,这问题就直观了, 不过具体处理起来大部分时间在纠结左移右移:
00// eczn_btoa_v1.tsx 01 02import { _6bitsToa } from './base64-alphabet'; 03 04/** 05 * 注意到: 06 * 3 个字节共 3 * 8 = 24 位 07 * 4 个 base64 字母共 4 * 6 = 24 位 08 * 因此可以三个字节三个字节的去处理, 09 * 三个字节每个位跟 base64 字母的对应关系: 10 * 11 * 000000000000000000000000 (共 24 位) 12 * !!!!!! 13 * @@@@@@ 14 * $$$$$$ 15 * %%%%%% (每行对应一个字母, 各占6位) 16 */ 17export function eczn_btoa_v1(buf: string): string { 18 let result = ''; 19 for (let i = 0; i < buf.length; i += 3) { 20 const b0 = buf[i + 0].charCodeAt(0); 21 // 传了 = 或者空了就当成 0 看待 22 const b1 = buf[i + 1]?.charCodeAt(0) ?? 0; 23 const b2 = buf[i + 2]?.charCodeAt(0) ?? 0; 24 25 // 111001 111001 101000 000000 26 // !!!!!! !!==== ====xx xxxxxx 27 28 const _1 = _6bitsToa( 29 // 取出 b0 的高 6 位 30 (b0 & 0b11111100) >> 2 31 ); 32 result = result.concat(_1); 33 34 const _2 = _6bitsToa( 35 // 取出 b0 的低 2 位, 36 // 然后再拼接 b1 的高 4 位 37 ((b0 & 0b00000011) << 4) + ((b1 & 0b11110000) >> 4) 38 ); 39 result = result.concat(_2); 40 41 // 填 = 等于号处理,然后 break 掉 42 if (buf[i + 1] === undefined) { 43 result = result.concat('='); 44 result = result.concat('='); 45 break; 46 } 47 48 const _3 = _6bitsToa( 49 // 取 b1 的低四位, 50 // 然后再拼接 b2 的高 2 位 51 ((b1 & 0b00001111) << 2) + ((b2 & 0b11000000) >> 6) 52 ); 53 result = result.concat(_3); 54 55 // 填 = 等于号处理,然后 break 掉 56 if (buf[i + 2] === undefined) { 57 result = result.concat('='); 58 break; 59 } 60 61 // 取 b2 的低 6 位 62 const _4 = _6bitsToa(b2 & 0b00111111); 63 result = result.concat(_4); 64 } 65 66 return result; 67}
我们手动对齐了 4 和 3 的 bits 位差,因此代码看起来特别糟糕, 如上各种 << 和 >>, 最关键是 = 等于号的填充写的很恶心,因为
i += 3
的原因就会导致出现 undefined 的问题,因此要特别小心出问题,实现后的效果如下:eczn_btoa_v1("\u0000\u0000@") ===>
"AABA"
# 但是, 注意到 ... ↵
注意到 int32 本身就可以当成 4 字节 buffer 来用, 类比到 ts 的
number
它也可以实现类似功用,那么基于这样的想法就可以避免前面版本的 i += 3
的复杂处理了, 因此写出第二个版本 eczn_btoa_v200// eczn_btoa_v2.tsx 01 02import { _6bitsToa } from './base64-alphabet'; 03 04export function eczn_btoa_v2(str: string): string { 05 let result = ''; 06 let buf = 0; 07 let bitCount = 0; 08 09 for (let i = 0; i < str.length; i ++) { 10 const b0 = str.charCodeAt(i); 11 buf = (buf << 8) + b0; 12 bitCount += 8; 13 14 while (bitCount >= 6) { // 111111xx 15 result += _6bitsToa(buf >> (bitCount - 6)); 16 buf = buf & ((0b1 << (bitCount - 6)) - 1) 17 bitCount -= 6; 18 } 19 } 20 21 // 最后剩下一点处理一下 22 if (bitCount !== 0) { 23 result += _6bitsToa(buf << (6 - bitCount)); 24 } 25 26 // 填等于号 27 if ((result.length % 4) !== 0) { 28 result += '='.repeat(result.length % 4); 29 } 30 31 return result; 32}
eczn_btoa_v2("\u0000\u0000@") ===>
"AABA"
# atob 呢? ↵
btoa 前面已经写完了,这里补一下反向操作的 atob 实现
00import { aTo6bits } from './base64-alphabet'; 01 02export function eczn_atob(str: string): string { 03 let result = ''; 04 let buf = 0; 05 let bitCount = 0; 06 07 for (let i = 0; i < str.length; i ++) { 08 if (str[i] === '=') break; // 读到等于号不要了 09 const bits = aTo6bits(str[i]); 10 buf = (buf << 6) + bits; 11 bitCount += 6; 12 13 while (bitCount >= 8) { // 超了 14 let byte = buf; 15 result += String.fromCharCode(byte >> (bitCount - 8)); 16 buf = buf & ((0b1 << (bitCount - 8)) - 1); 17 bitCount -= 8; 18 } 19 } 20 21 // 如果 buf 本身就是 0 的话直接不要了 22 if (bitCount !== 0 && buf !== 0) { 23 result += String.fromCharCode(buf << (8 - bitCount)); 24 } 25 return result; 26}
好了,本文差不多结束了,这里重新贴一下之前的 eczn_atob eczn_btoa demo:
eczn_atob("AABA") ===>
"\u0000\u0000@"
eczn_btoa_v2("\u0000\u0000@") ===>
"AABA"
下面附上原生的 atob 和 btoa 参考对比
globalThis.atob("AABA") ===>
"\u0000\u0000@"
globalThis.btoa("\u0000\u0000@") ===>
"AABA"